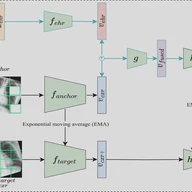
Multimodal masked siamese network improves chest X-ray representation learning
Self-supervised learning methods for medical images primarily rely on the imaging modality during pretraining. Although such approaches deliver promising results, they do not take advantage of the associated patient or scan information collected within Electronic Health Records (EHR). This study aims to develop a multimodal pretraining approach for chest radiographs that considers EHR data incorporation as an additional modality that during training. We propose to incorporate EHR data during self-supervised pretraining with a Masked Siamese Network (MSN) to enhance the quality of chest radiograph representations. We investigate three types of EHR data, including demographic, scan metadata, and inpatient stay information. We evaluate the multimodal MSN on three publicly available chest X-ray datasets, MIMIC-CXR, CheXpert, and NIH-14, using two vision transformer (ViT) backbones, specifically ViT-Tiny and ViT-Small. In assessing the quality of the representations through linear evaluation, our proposed method demonstrates significant improvement compared to vanilla MSN and state-of-the-art self-supervised learning baselines. In particular, our proposed method achieves an improvement of of 2% in the Area Under the Receiver Operating Characteristic Curve (AUROC) compared to vanilla MSN and 5% to 8% compared to other baselines, including uni-modal ones. Furthermore, our findings reveal that demographic features provide the most significant performance improvement. Our work highlights the potential of EHR-enhanced self-supervised pretraining for medical imaging and opens opportunities for future research to address limitations in existing representation learning methods for other medical imaging modalities, such as neuro-, ophthalmic, and sonar imaging.
Sep 28, 2024

Multimodal machine learning for stroke prognosis and diagnosis: A systematic review
Stroke is a life-threatening medical condition that could lead to mortality or significant sensorimotor deficits. Various machine learning techniques have been successfully used to detect and predict stroke-related outcomes. Considering the diversity in the type of clinical modalities involved during management of patients with stroke, such as medical images, bio-signals, and clinical data, multimodal machine learning has become increasingly popular. Thus, we conducted a systematic literature review to understand the current status of state-of-the-art multimodal machine learning methods for stroke prognosis and diagnosis. Following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines during literature search and selection, our results show that the most dominant techniques are related to the fusion paradigm, specifically early, joint and late fusion. We discuss opportunities to leverage other multimodal learning paradigms, such as multimodal translation and alignment, which are generally less explored. We also discuss the scale of datasets and types of modalities used to develop existing models, highlighting opportunities for the creation of more diverse multimodal datasets. Finally, we present ongoing challenges and provide a set of recommendations to drive the next generation of multimodal learning methods for improved prognosis and diagnosis of patients with stroke.
Aug 21, 2024